🔖 Note
本文 是少数派 2020 年度征文活动 的入围文章。发布于 2021 年 1 月 29 日,最近更新于 2023 年 2 月 6 日。
目录
- 存在什么问题?
- 使用 Markdown
- 使用 Pandoc
- 用 BibTeX/BibLaTeX 存储引文数据
- 在 Markdown 中引用文献
- Markdown 转换为 DOCX
- Markdown 转换为 PDF
- One More Thing
- 结语
存在什么问题?
为什么不使用 Microsoft Word?
学术论文写作使用 Microsoft Word 或类似的富文本编辑软件,可以说是学术圈特别是人文社科领域「事实上」的标准。但是,如同微信一样,流行并不代表它好用:
- Word 无法实现「内容与格式分离」。所见即所得(What You See Is What You Get)的编辑方式让用户难以专注于文章内容,不可避免会在写作过程中去调整格式,不仅写作体验很差,更造成写作效率的降低。
- Word 原生不支持引用学术文献。尽管 Microsoft Word 力图使所有工作都集中在一个 DOCX 文件内部完成 1,但它原生对文献引用却没有很好的支持,一般需要 EndNote、Mendeley、Zotero 等工具的辅助,但这一方式并不算优雅,不能实现理想中的 Cite While You Write(CWYW)2。
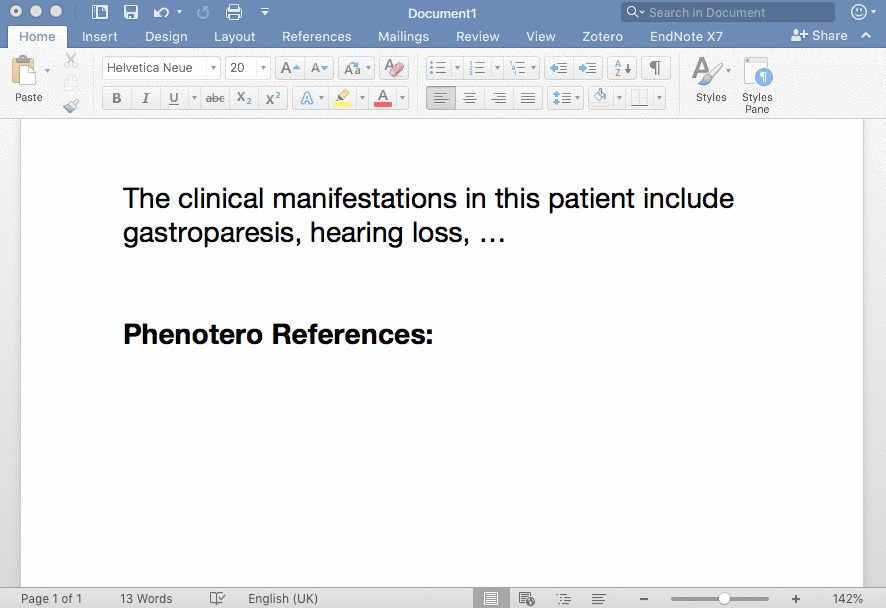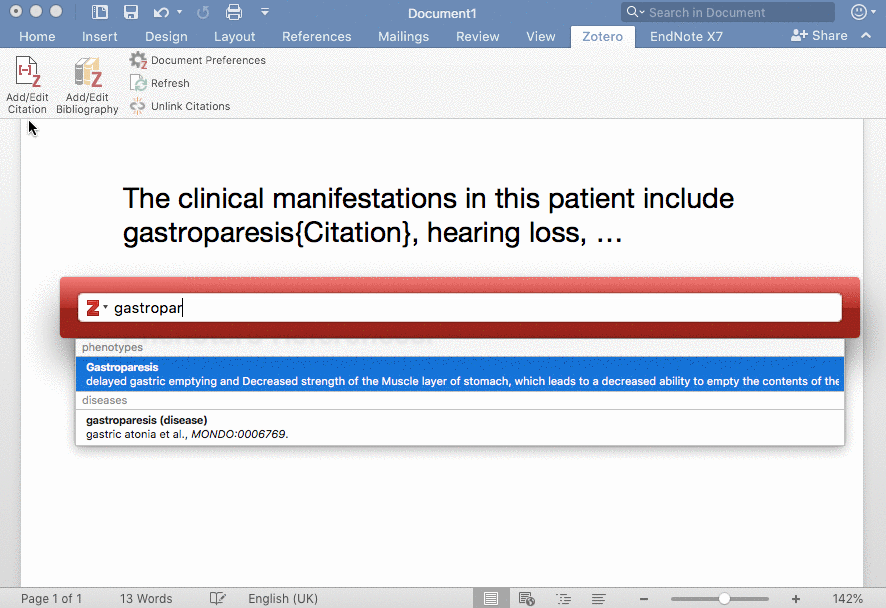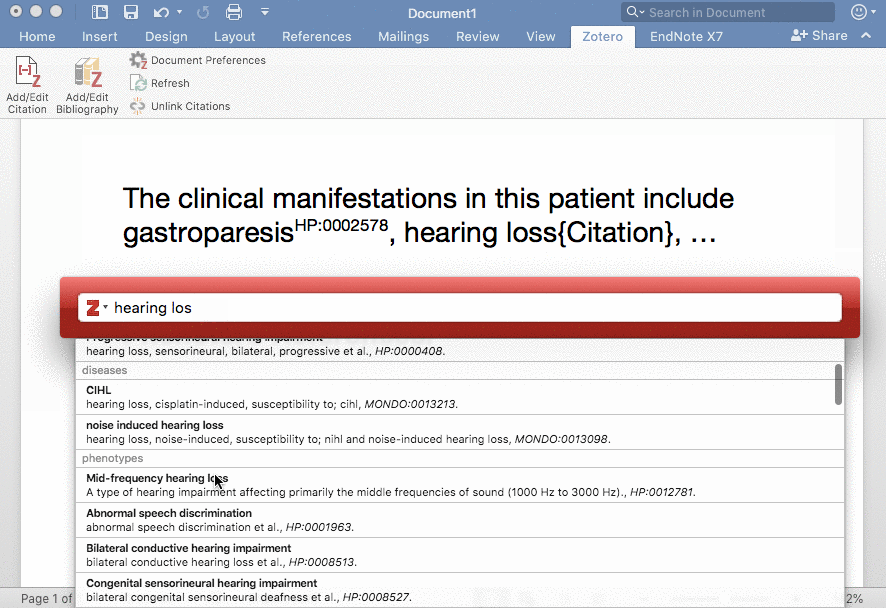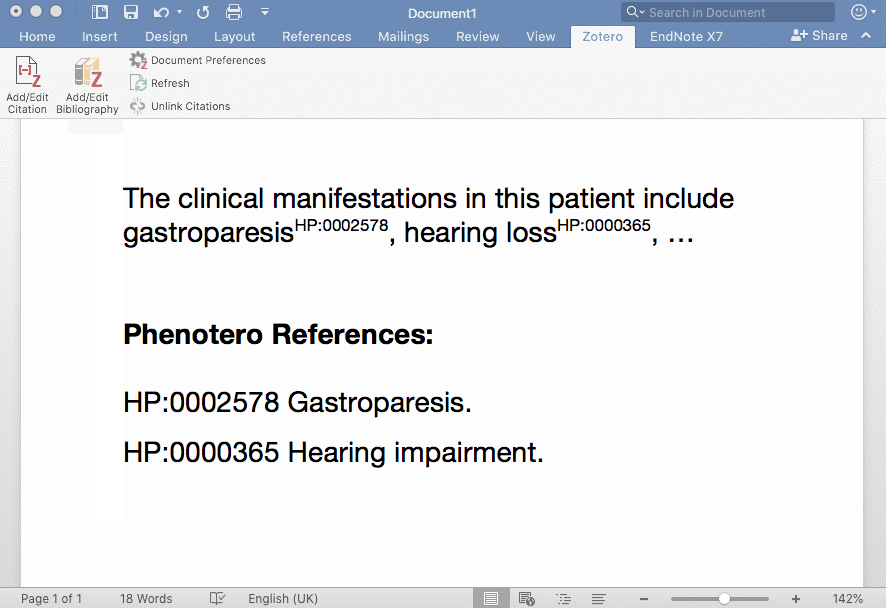 在 Word 中使用 Zotero 插入 Citation,图片来源于 https://phenotero.github.io
在 Word 中使用 Zotero 插入 Citation,图片来源于 https://phenotero.github.io
- Word 的设计不符合 Unix 哲学。作为 Mac 用户,我喜欢使用纯文本(Plain Text),并用 Git 对其进行版本控制。虽然我曾尝试 对 DOCX 文件进行「纯文本式」版本控制,但效果并不算满意。
- Word 在 macOS 上体验非常糟糕。这可以说是「压死骆驼的最后一根稻草」,让我不得不放弃使用它。姑且不谈 Word 打开长文档时的漫长等待与卡顿,仅仅是查看一下文档元数据、复制一段文字,就会询问我是否要保存,实在是难以理解 Word 的设计逻辑。
 我讨厌使用 Microsoft Word,图片来源于视频 https://youtu.be/JG4fqd8pEgE 截图
我讨厌使用 Microsoft Word,图片来源于视频 https://youtu.be/JG4fqd8pEgE 截图
为什么不选择 LaTeX?
LaTeX 非常酷,超级强大,能够精确控制文档的每一个细节,从第一次接触 LaTeX 起,我就深深被它的排版效果所折服,尽管诞生于上世纪 80 年代,但 LaTeX 至今仍是科学论文排版的最强工具。
 在 VS Code 中结合插件 LaTeX Workshop 使用 LaTeX
在 VS Code 中结合插件 LaTeX Workshop 使用 LaTeX
我的本科毕业论文使用 LaTeX 完成,并且几乎所有的插图也是直接用 PGF/TikZ 绘制的,虽然最终的排版效果非常好,但在这一过程中,我也意识到 LaTeX 的几个问题:
- LaTeX 只能生成 PDF。这本身没有任何问题,但是,在很多情况下,DOCX 是对方可接受的唯一格式 3,尽管网上所谓「PDF 转 Word」的软件或在线服务多如牛毛,但没有一个让人满意的。
 国家社会科学基金项目申报要求提供「WORD 文件格式,图片来源于 http://www.nopss.gov.cn/n1/2021/0106/c219469-31991309.html
国家社会科学基金项目申报要求提供「WORD 文件格式,图片来源于 http://www.nopss.gov.cn/n1/2021/0106/c219469-31991309.html
- LaTeX 难以做到 内容与格式分离。虽然 LaTeX 的基本设计原则之一就是内容与格式相分离,但就我的使用体验来说,这很难做到,因为 LaTeX 过于强大,任何一个细节都变得极具「把玩性」,往往陷入「写文章十分钟,调整样式两小时」的情况,逐渐偏离正题并且还乐在其中不自知 😂️。
为了解决 Microsoft Word 和 LaTeX 存在的这些问题,接下来我将介绍以 Markdown 写作学术论文,用 Pandoc 将其转换为其他文件格式,并对参考文献和中文排版的一些细节进行调整。其中引文样式采用中文用户使用非常普遍的 GB/T-7714-2015 信息与文献 参考文献著录规则 的著者-出版年制,引文数据只使用一份文件 ref.bib,最终实现输出排版完美的 DOCX 和 PDF,主要流程见下图。
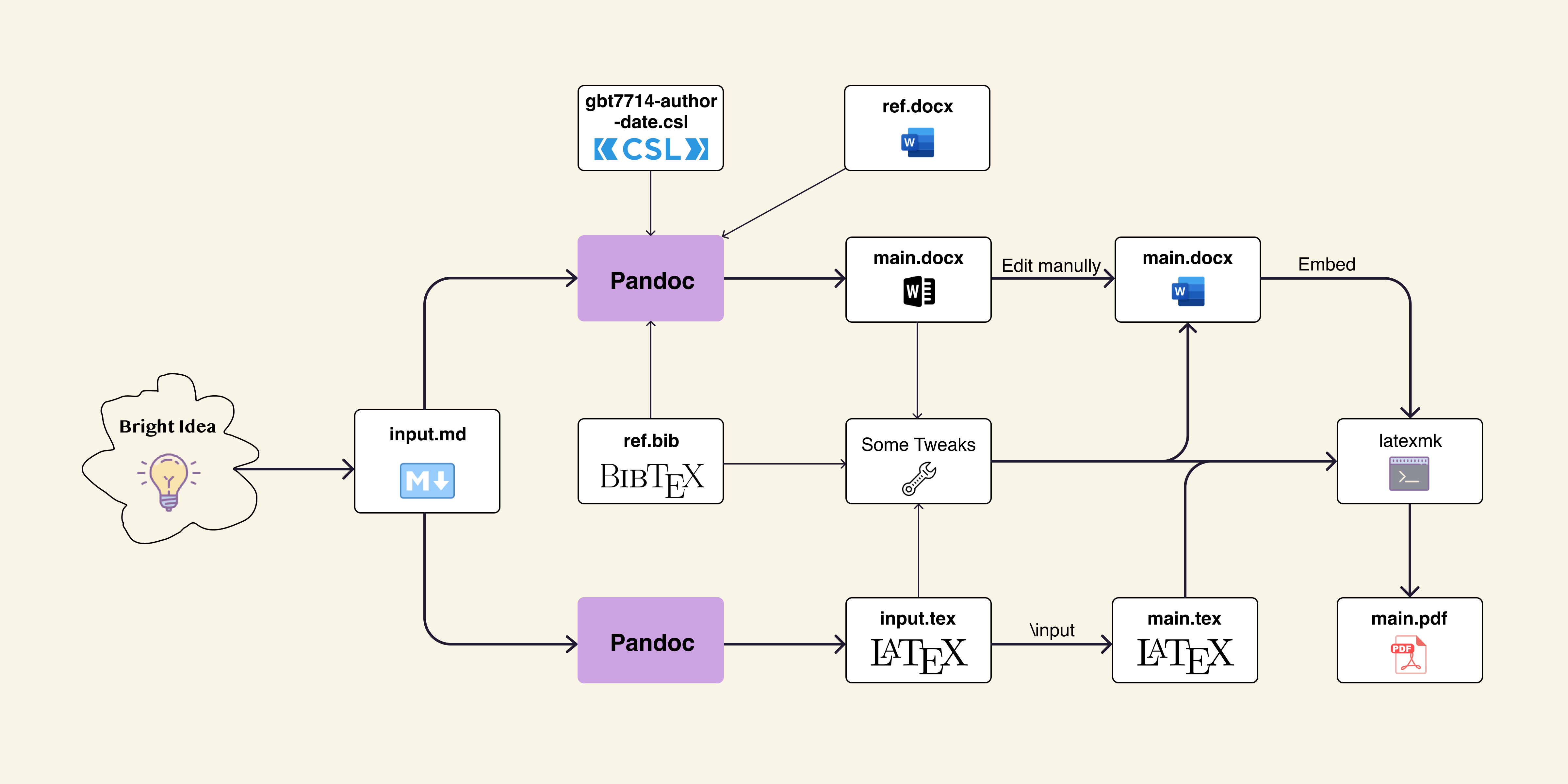 纯文本学术写作流程
纯文本学术写作流程
使用 Markdown
学术期刊 PeerJ Computer Science 过去五年里 浏览量前五 的一篇 论文 里列举了 8 种当前科学出版的标准格式,包括我们熟悉的 DOCX、PDF 等,但最让我惊喜的是 Markdown 也名列其中。
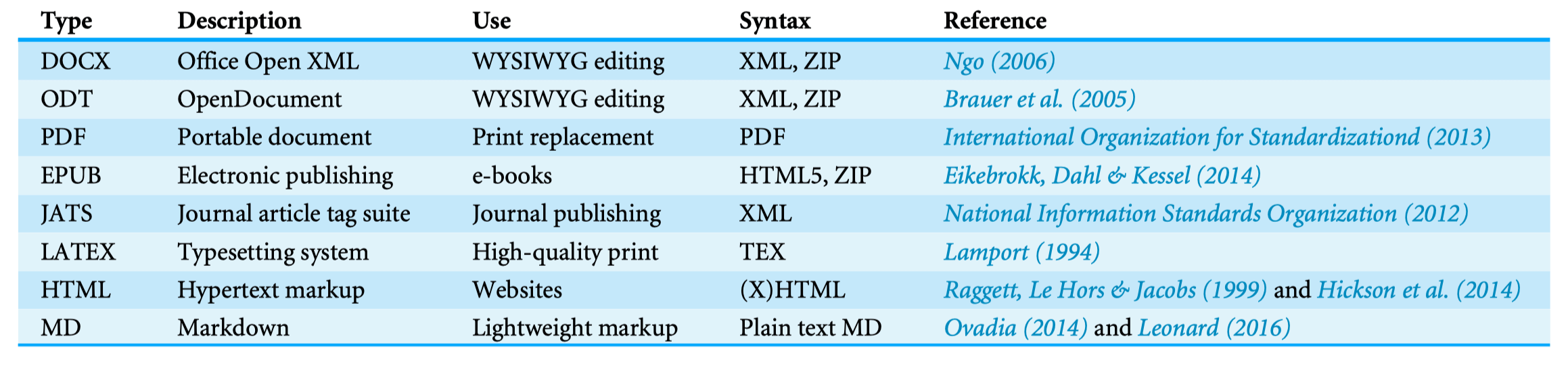 几种主流文件出版格式,来源于 https://doi.org/10.7717/peerjcs.112/table-1
几种主流文件出版格式,来源于 https://doi.org/10.7717/peerjcs.112/table-1
Markdown 由 John Gruber 和 Aaron Swartz 于 2004 年开发,是一种轻量级标记语言,它的语法非常简单,15 分钟即可快速上手。
 Markdown 基本语法
Markdown 基本语法
John Gruber 坚持 Markdown 应该保持极简,没有制定一个统一的标准,导致 Markdown 有很多「方言」,并且原生 Markdown 不支持脚注、表格等形式,因此,Markdown 作为一种纯文本格式(Plain Text),确实显得平平无奇。不过,时间已来到 2021 年,在许多人的努力下,Markdown 已经变得相当酷。正如 Markdown.app 的作者 @海波 所说:
并不是 Markdown 很酷,而是一帮相对比较酷的人,他们共同选择了 Markdown。
对于这句话,我非常赞同。Markdown 没有 LaTeX 那样复杂,又避免了 Microsoft Word 所见即所得的编辑方式,同时又保持了纯文本的优雅,让用户可以专注于文章内容,沉寂于写作之中。借助外部工具,又可以实现非常丰富的功能,在后文我们将看到,Pandoc 彻底改变了 Markdown,使得平平无奇的 Markdown 大放异彩,因此我们可以说,Markdown 的未来 一片光明 4!
 在 VS Code 中写 Markdown 并进行版本控制
在 VS Code 中写 Markdown 并进行版本控制
使用 Pandoc
Pandoc 被称为文件格式转换的「瑞士军刀」,由加州大学伯克利分校哲学系 John MacFarlane 教授使用 Haskell 语言开发,在 GitHub 上拥有超过 21000 个 Star,几乎可以实现所有标记语言格式(Markup Format)的相互转换。
打开 Pandoc 官网,选择你的操作系统对应的版本,下载并安装 Pandoc,在 macOS 上可以通过 Homebrew 快速安装:
|
|
Pandoc 是一个命令行工具,没有图形化界面 5,安装好之后,进入终端(Terminal),输入:
|
|
如果输出结果为 Pandoc 版本及其相关信息,则表示安装成功。Pandoc 的基本使用方式如下:
|
|
例如,对于一个名为 input.md 的 Markdown 文件,将其转换为 output.docx 的命令为:
|
|
Pandoc 的使用手册 非常详细,你可以在遇到任何问题时进行查阅,或者在终端中输入:
|
|
进行浏览或查阅。
用 BibTeX/BibLaTeX 存储引文数据
据我观察,在 Microsoft Word 中引用文献一般有「三重境界」:
- 徒手在文后写参考文献表(bibliography),正文中不引用(citation)
- 从数据库网站拷贝格式化的引文格式,粘贴到 DOCX 文件最后的参考文献表中(需要注意的是,CNKI 的 GB/T 7714-2015 格式引文不完全符合国标的要求。)
- 通过 Zotero 等文献管理工具的 Word 插件将参考文献以宏的方式插入 DOCX 文件
可以注意到,这三种方式都没有将引文数据单独存储,难以实现参考文献的复用。试想一种情况,你需要将你的大作集结出版,出版社要求的格式是 chicago-author-date,而你之前使用的是 GB/T-7714-2015-author-date,并且还有重复的条目,这种情况下,上述「三重境界」都无法很好地解决,基本上只能靠手动修改了。
基于工程师模式(Engineering Model),文件应该以纯文本形式存储,针对引文数据,就是使用 BibTeX 或 BibLaTeX 6。一个典型的 BibTeX 文件是下面这样滴:
|
|
上面例子中的 ho2014 被称为 citekey。Zotero 插件 Better BibTeX 可以非常方便地将文献导出为各种格式,例如下图,从 Zotero 中导出 BibLaTeX 格式的引文数据,并存储为 ref.bib。如果导出 Zotero 中的某一个文献目录,推荐勾选 Keep updated 选项,这样 Zotero 中条目信息更新,ref.bib 文件中的内容也会自动更新,避免手动进行添加或删除。
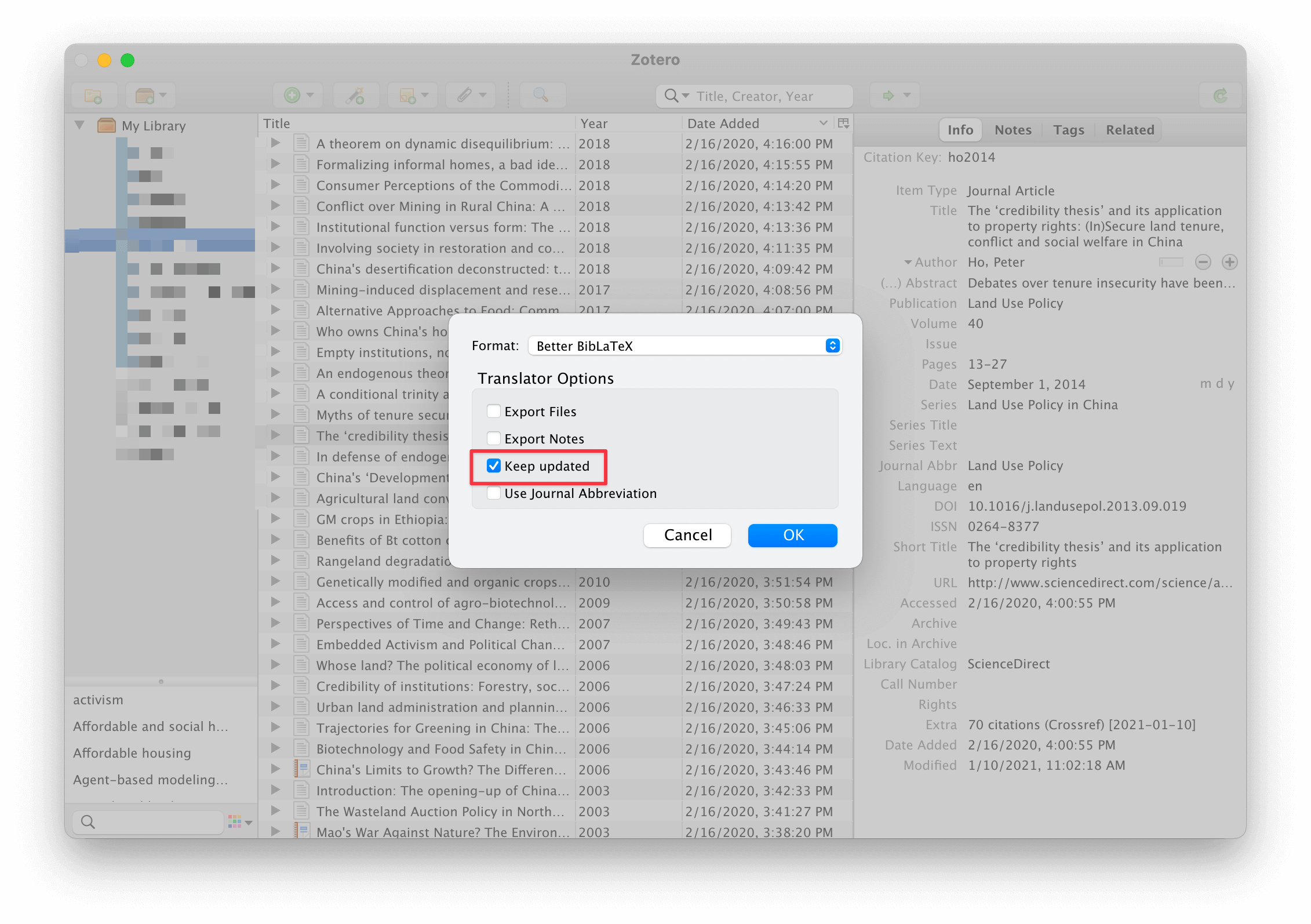 Better BibTeX for Zotero 导出为 BibLaTeX 格式的引文数据
Better BibTeX for Zotero 导出为 BibLaTeX 格式的引文数据
作为纯文本的 BibTeX/BibLaTeX 不仅可以被 LaTeX、Markdown 等其他文件使用,在 Pandoc 的加持下,它还可以「自成一派」,独立生成格式化的参考文献,例如:
|
|
这条命令中,Pandoc 使用 IEEE 的引文样式 7,调用 citeproc 处理参考文献,将 ref.bib 转换为 ref.docx,这在某些情况下很有用,可以看出用 BibTeX/BibLaTeX 存储引文数据的优势。
在 Markdown 中引用文献
原生 Markdown 不支持引用文献,而 Pandoc 应该是目前唯一能够处理 Markdown 文献引用的工具,因此,在 Markdown 中引用文献,实质就是遵循 Pandoc 的 文献引用语法 进行写作。
Pandoc 的文献引用语法
Pandoc 的引用语法非常简单,只有 @citekey 和 [@citekey] 两种形式,即在 Markdown 文件中这样写:
|
|
这里引用的三篇文献,没有方括号的 @ho2014 是句中引用,通过 Pandoc 转换后形如 Ho (2014),而另外两个则是句末引用,转换后形如 (Sun, 2015; Soman, 2018)。因此,上面这段示例的最终结果如下所示:
|
|
以上是针对著者-出版年制的引用,如果是顺序编码制,则只需要用到有方括号包裹的句末引用的形式,即形如 [@sun2015]。
特别地,著者-出版年制下,在句中引用时,引用同一作者不同年份的文献需要这样写:
|
|
生成的结果如下:
|
|
如果需要引用 ref.bib 中的所有文献(即无论文献的 citekey 是否出现在正文中),你可以在 Markdown 文件的开头这样写:
|
|
实现 Cite While You Write
大多数情况下,我在 Visual Studio Code 中写需要引用文献的 Markdown,Pandoc Citer 这个插件可以实现真正的 Cite While You Write,其效果如下图所示:
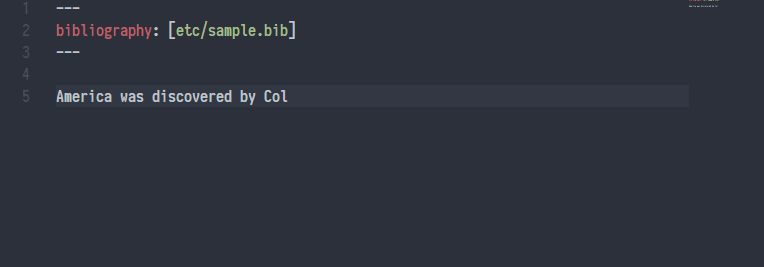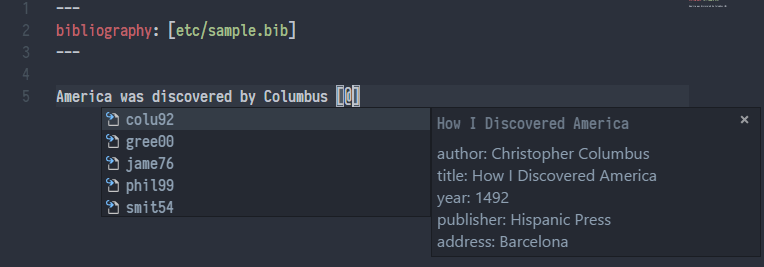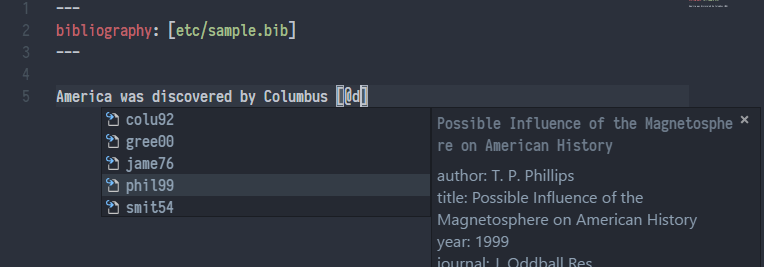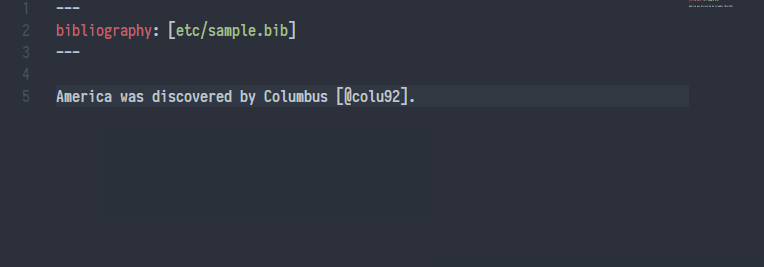 使用 Pandoc Citer 实现 Cite While You Write,图片来源于 https://github.com/notZaki/PandocCiter
使用 Pandoc Citer 实现 Cite While You Write,图片来源于 https://github.com/notZaki/PandocCiter
除此之外,Zettlr 也可以实现类似的功能,但需要在 Preference -> Export 中指定引文数据存储路径,效果如下图:
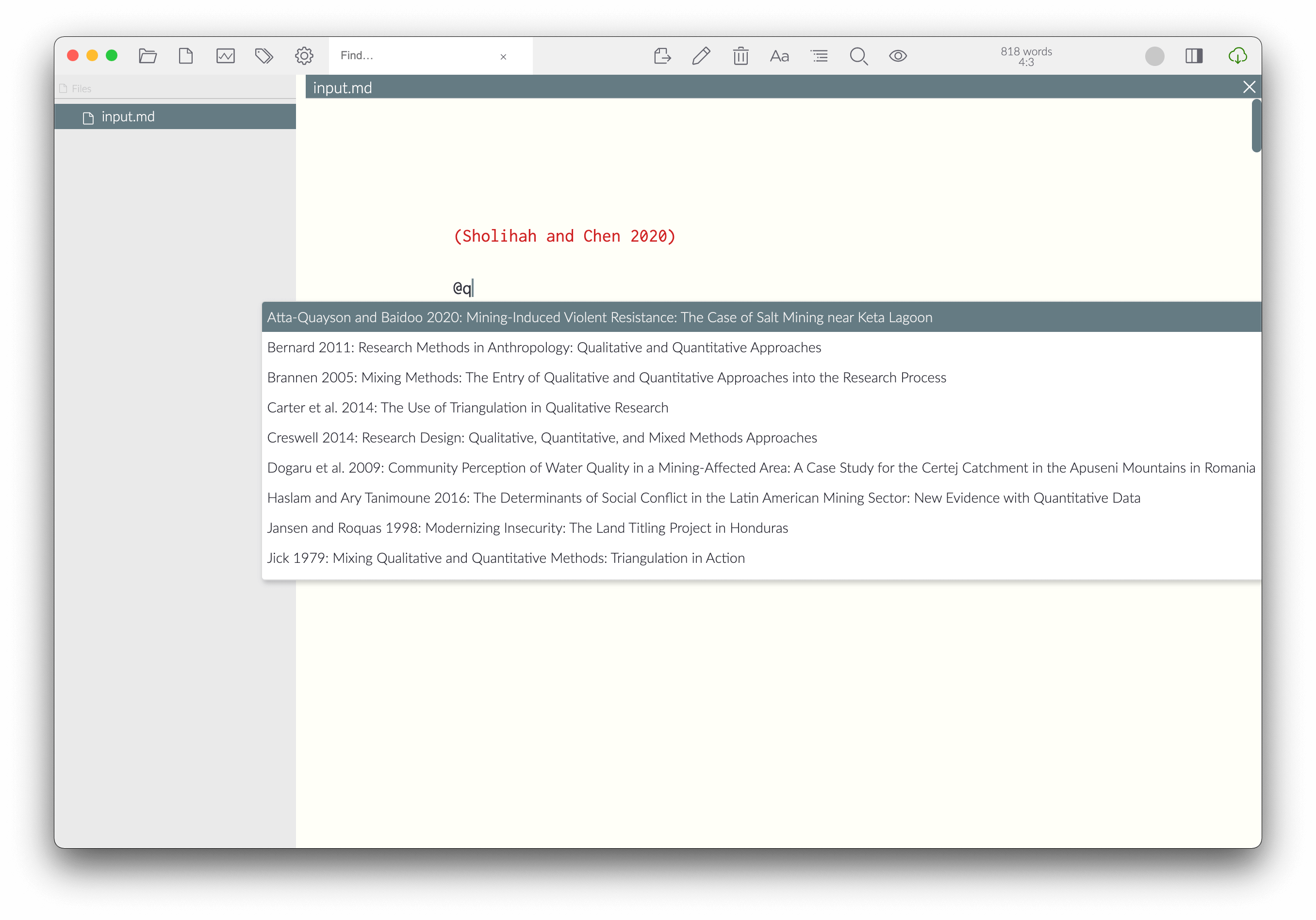 在 Zettlr 中实现 Cite While You Write
在 Zettlr 中实现 Cite While You Write
关于 Cite While You Write,还有其他一些解决方案,如果你有需要,可以进一步研究:
- Citation Picker for Zotero:一个 Visual Studio Code 插件,可以在 VS Code 中调出 Zotero 引用面板,与 Zotero 自带的插件 Zotero Word for Mac Integration 类似
- zotpick-applescript:Apple Script 实现调出 Zotero 引用面板,使用方法可参考 这篇文章
- ZotHero:一个 Alfred Workflow,用来全局搜索 Zotero 数据库,快速复制 citekey、citation、bibliography 等
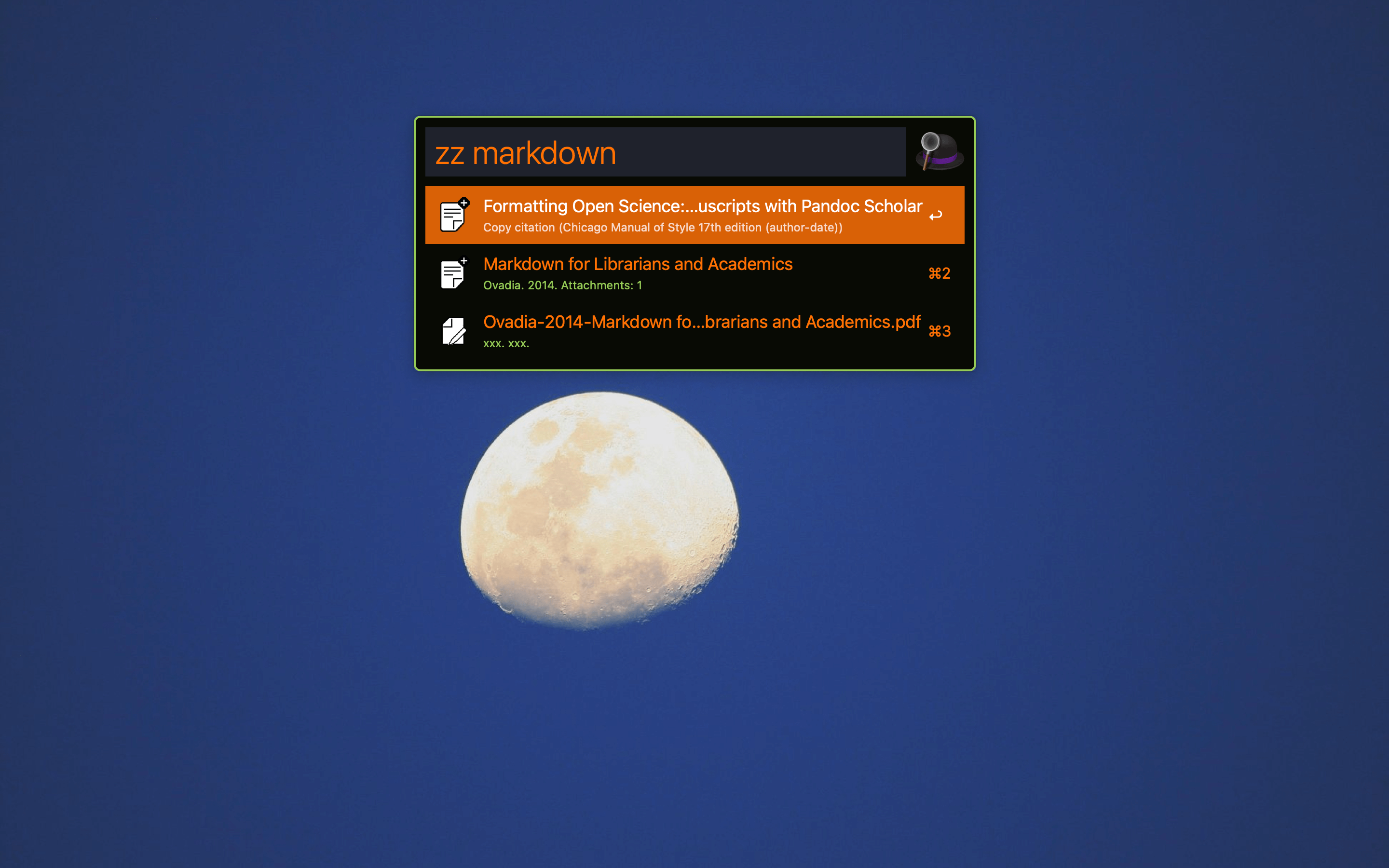 在 Alfred 中用 ZotHero 搜索 Zotero 数据库
在 Alfred 中用 ZotHero 搜索 Zotero 数据库
Markdown 转换为 DOCX
在 input.md 中写好文章的内容之后,接下来在终端中输入下面的命令,就可以将 Markdown 转换为 DOCX 文件:
|
|
pandoc:执行 Pandoc 命令--citeproc:处理文献引用,也可用-C代替--number-sections:对各级标题编号,形如1, 1.1, 1.1.1,也可用-N代替--csl china-national-standard-gb-t-7714-2015-author-date.csl:指定参考文献样式,这里使用的是 GB/T 7714-2015 的著者-出版年制格式,更多样式可以前往 Zotero Style Repository 下载--bibliography ref.bib:引文数据文件,即前文由 Better BibTeX for Zotero 导出的ref.bib-M reference-section-title="参考文献":设置参考文献表的标题为「参考文献」,不编号-M link-citations=true:设置正文引用可以超链接到参考文献表中相应的条目,默认为false--reference-doc ref.docx:参考的 DOCX 文件格式,根据 Pandoc 使用手册,最好的方式是通过命令pandoc -o custom-reference.docx --print-default-data-file reference.docx得到 Pandoc 的默认 DOCX 文件,然后用 Microsoft Word 打开这个文件,根据你的喜好进行修改input.md:存储文章内容的 Markdown 文件-o main.docx:输出 DOCX 文件\:反斜杠,表示换行,你也可以删除它,把所有命令写在一行。
一般来说,如果你的论文是用英文写的话,得到的 main.docx 基本上就是一个完美的结果,不需要做任何修改。然而,对于中文用户来说,还有一些细节需要进行调整。
「et al.」与「等」
《信息与文献 参考文献著录规则 GB/T-7714-2015》第 15 页 10.2.2 节规定:
正文中引用多著者文献时,对欧美著者只需标注第一个著者的姓,其后附「et al.」;对于中国著者应标注第一个著者的姓名,其后附「等」字。姓氏与「et al.」「等」之间留适当空隙。
然而,由于我们使用的 china-national-standard-gb-t-7714-2015-author-date.csl 基于 Citation Style Language,不能同时处理多语言,无法实现这一需求 8。如何实现「et al.」 与「等」的混合使用,是很多同学非常希望解决的 问题,各路网友给出了自己的 解决方案。下面提供我的两种解决方法。
在 Microsoft Word 中查找替换
使用 Microsoft Word 打开转换得到的 main.docx,打开「高级查找和替换」,勾选「使用通配符」,在「查找内容」栏填入 ([a-zA-Z])(? )(等),「替换为」栏填入 \1\2et al.,然后点击「全部替换」,就可以同时把正文、脚注和参考文献表中所有英文作者名后的 等 替换为 et al.。
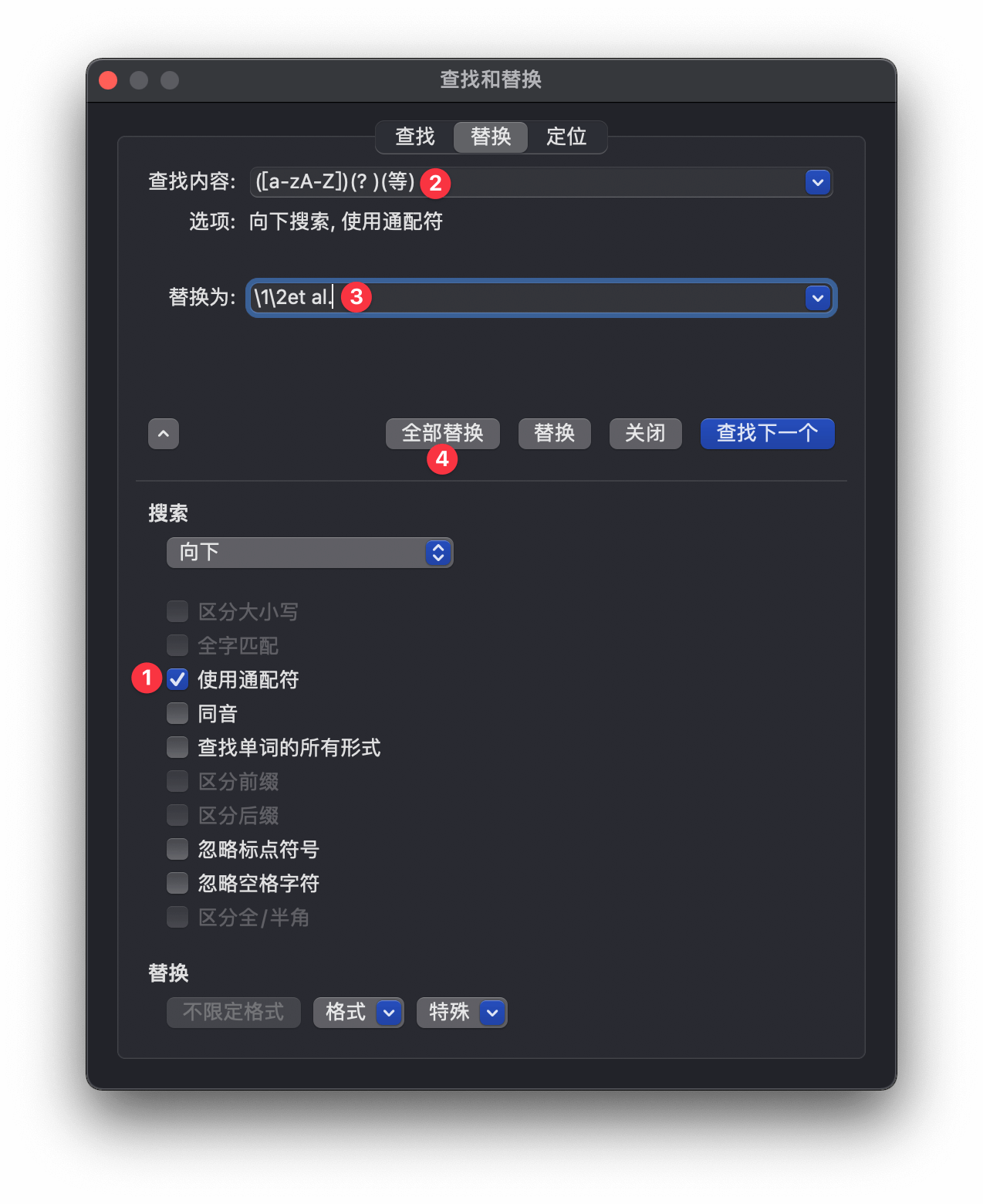 在 Microsoft Word 中使用通配符进行查找替换
在 Microsoft Word 中使用通配符进行查找替换
使用正则表达式查找替换
众所周知,DOCX 是一种压缩文件,那么为什么不把先把 DOCX 解压缩之后再查找替换,然后再压缩回来呢 9?
在终端中进入 main.docx 所在目录,然后输入:
|
|
就可以将 Pandoc 转换得到的 main.docx 解压缩到文件夹 unzipped,其目录结构如下:
|
|
在这么多文件中,我们需要查找替换的内容只存储在 word/document.xml 和 word/footnotes.xml 这两个纯文本文件中,于是就可以用下面这几行代码来完成这一操作:
|
|
最后两行代码用 正则表达式 来匹配查找与替换的内容,并用 Perl 来进行查找替换的操作。
关于正则表达式,推荐使用 regex101 进行学习与测试。如果你喜欢在本地应用中使用正则表达式,可以试试强大的 BBEdit。除了 Perl 之外,也可以用 Sed 和 Awk 来完成查找替换的操作,不过 Perl 对 Unicode 字符支持更加友好,这也是我使用 Perl 的原因。在 macOS 上,这些工具都不需要额外安装,开箱即用。
📖 关联阅读
移除多余的空格 10
Pandoc 的句中引用语法前必须要有一个空格,也即是没有中括号包裹的 citekey 前一定要有一个空格(段落开头除外),这对于英文写作完全没有问题,因为每个英语单词之前都有空格。但是在中文排版中,汉字之间一般没有空格。如果在 Markdown 中这样引用:
|
|
那么 @wang2015, @li2018, @feng2019 的前面分别会存在一个多余的空格 11,这是不符合中文排版习惯的。
Pandoc 提供了一个 Lua Filter 来移除句中引用时这个多余的空格:
|
|
使用方法非常简单,只需要将上面这 18 行代码复制,粘贴到文本编辑器中,保存为 rsbc.lua,放置在工作目录,然后在前文命令的基础上,加上 --lua-filter rsbc.lua 即可,完整的例子如下:
|
|
如这个 Lua 脚本第四行的注释所写,只有一个句中引用前的空格才能被移除,下面这种情况:
|
|
@wang2015 [@wang2016] 前面的一个空格无法使用这个 Lua 脚本移除。不过没有关系,这里再次祭出「查找替换大法」,对解压缩后的 main.docx 进行查找替换:
|
|
正则表达式的匹配规则是标点符号 ,。;!? 中的任意一个,一段 XML 语句及其后面的一个空格,然后通过 Perl 进行替换,移除匹配到的空格。至于为什么不移除句中引用后面的空格,因为句中引用最后是一个半角括号 ),与其后面的文字(无论是中文还是西文)应该有一个空格,这是符合排版习惯的。 因此,结合 rsbc.lua 和「查找替换大法」这两种解决方式,我们就可以完美移除中文写作时句中引用导致的多余空格。
集中到一起
将上述提到的所有命令写到一个 Shell 脚本中:
|
|
将这个 Shell 脚本保存到工作目录,命名为 docx.sh,然后在终端中执行:
|
|
使 docx.sh 成为可执行文件,然后继续输入:
|
|
即可运行 docx.sh,得到 main.docx。至此,命令行的工作就结束了,接下来还有两个小细节需要在 Microsoft Word 中进行修改。
其他细节调整
- 调整包裹汉字的引号
首先需要明确,简体中文使用的双引号 “”(U+201C U+201D)和单引号 ‘’(U+2018 U+2019)与西文中的弯引号完全一致,也就是说,不像句号、逗号等有对应的全角标点符号,不存在所谓「全角引号」12。文字处理或者排版软件中,包裹汉字的引号看上去和包裹西文的引号不同,完全是由字体决定的。例如下图中,所有的引号都是一样的,即 U+201C 和 U+201D,但看上去明显不同,原因就是字体不同,看上去较宽的引号字体为「宋体」,而较窄的引号字体则为「Times New Roman」。
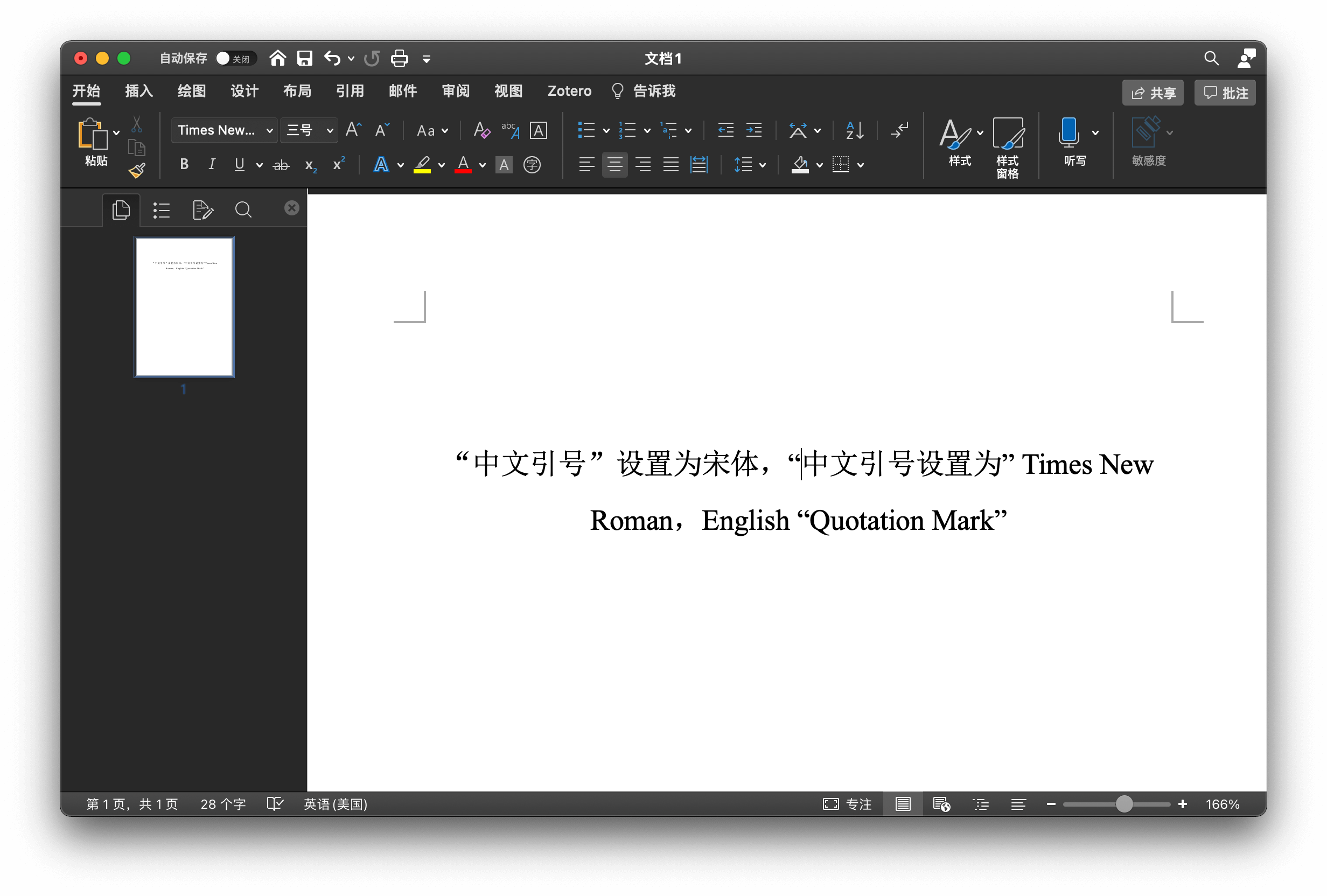 Microsoft Word 中同样的引号,呈现出不同的形态,原因在于字体不同
Microsoft Word 中同样的引号,呈现出不同的形态,原因在于字体不同
打开 Pandoc 转换得到的 main.docx,你会发现所有的引号都被视作「英语(美国)」,包裹汉字的引号看上去很窄,与汉字不搭配,这是因为 Pandoc 默认的本地化语言为英语,尽管这可以通过指定 lang: zh-CN 来解决,但这样又会将西文的引号弄成中文的样式,并且还会出现其他的 问题,因此并不推荐。
调整包裹汉字的引号非常简单,只需要在 Microsoft Word 中将中文文本内容选中,点击最下方的语言选项,将所选文字标记为「中文(中国)」,最后点击「确定」即可。
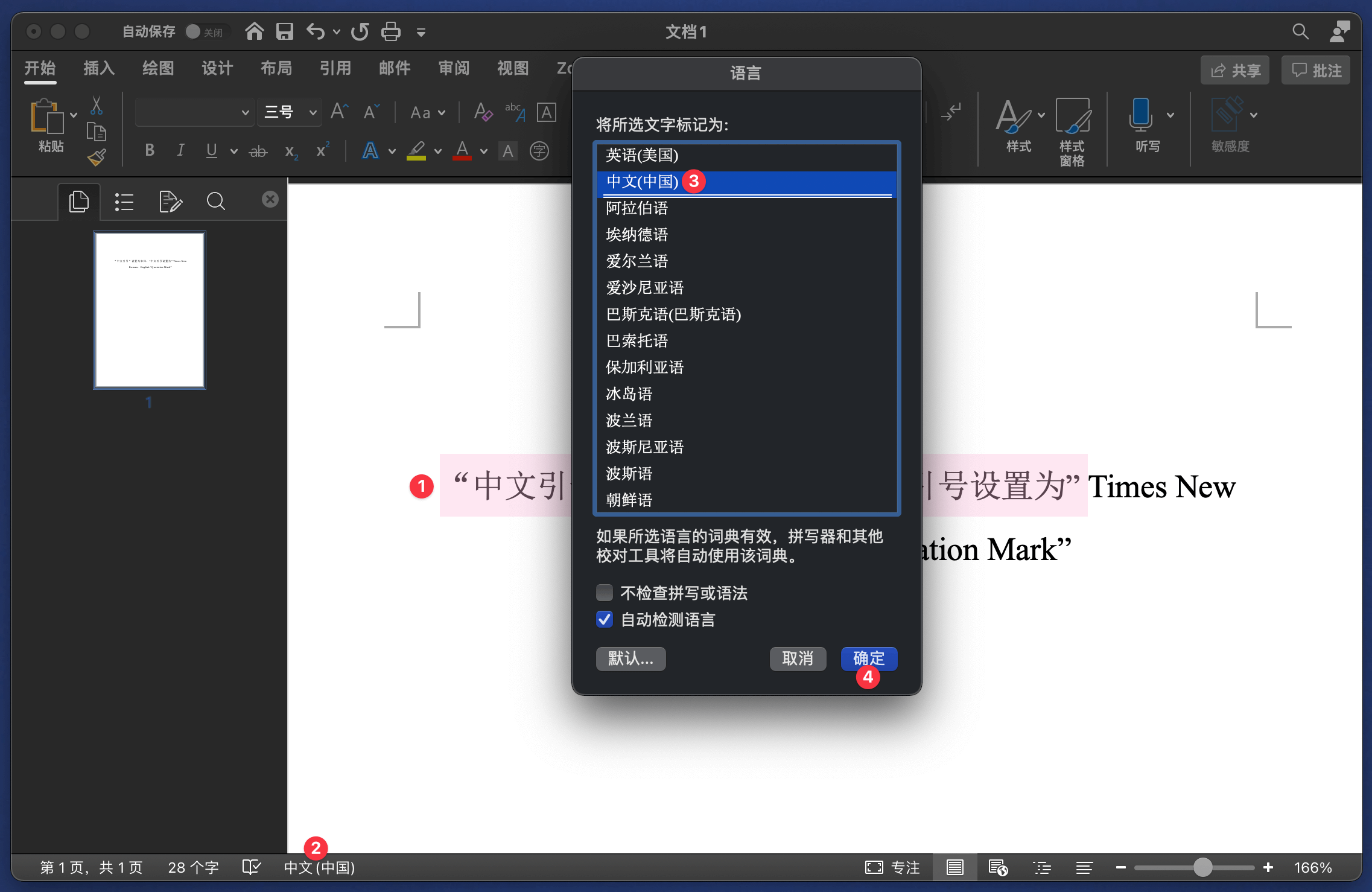 在 Microsoft Word 中将所选文字标记为中文
在 Microsoft Word 中将所选文字标记为中文
- 对中文参考文献表进行排序
《信息与文献 参考文献著录规则 GB/T-7714-2015》第 13 页 9.2 节规定:
参考文献表采用著者-出版年制组织时,各篇文献首先按文种集中,分为中文、日文、西文、俄文、其他文种 5 部分;然后按著者字顺和出版年排列。中文文献可以按著者汉语拼音字顺排列(参见 10.2),也可以按著者的笔画笔顺排列。
CSL 能够将参考文献表按文种集中,但它无法根据作者姓氏的拼音或笔画对中文文献进行排序,不得不在 Microsoft Word 中进行,不过好在步骤非常简单。只需选中参考文献表中所有的中文参考文献,然后点击「排序」,根据情况选择「拼音」或「笔画」排序。需要注意的是,按照拼音排序时需要检查一下是否存在多音字的情况,例如「曾」姓在排序中的拼音为 ceng,而正确的拼音应该为 zeng。
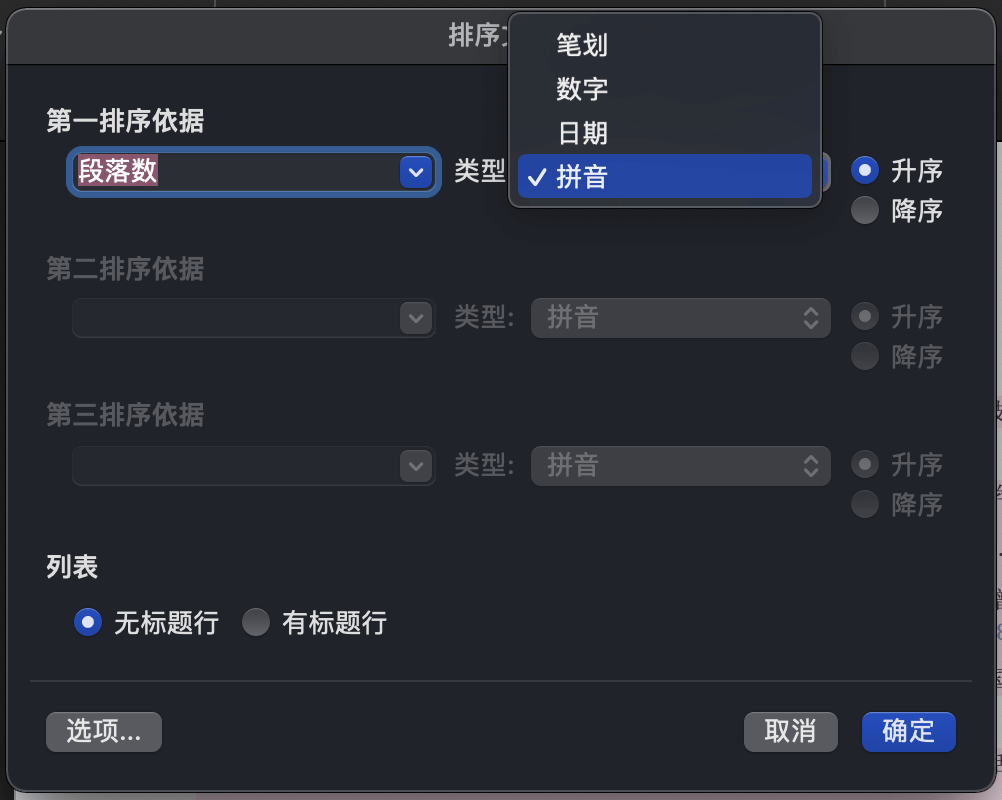 在 Microsoft Word 中对中文参考文献表排序
在 Microsoft Word 中对中文参考文献表排序
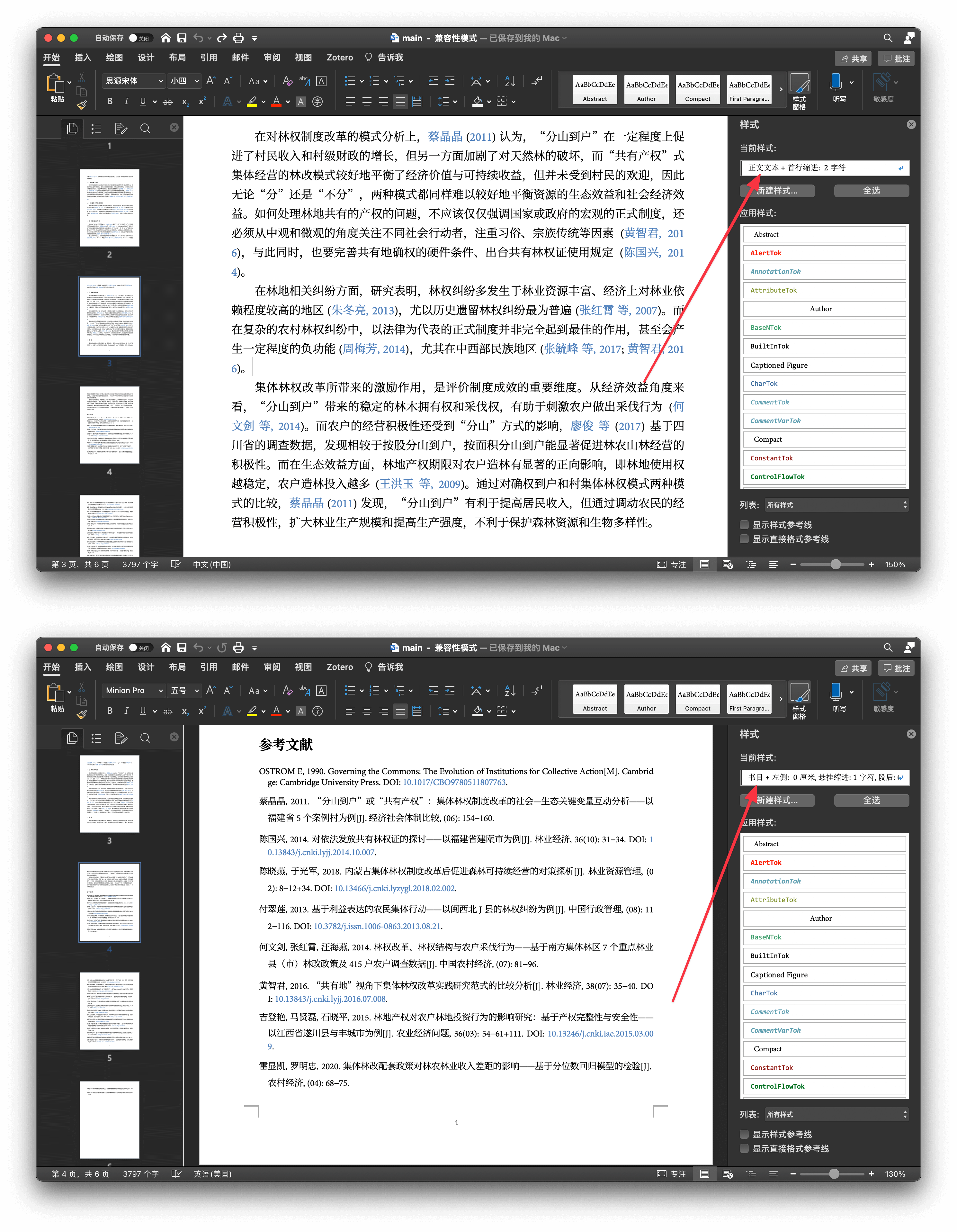 最终得到的 DOCX 文件。上图为正文的截图,样式为「正文文本」,其中的蓝色字体可点击跳转至文末相应的文献;下图为参考文献表的截图,Pandoc 完美地将其转换为 Word 中的样式「书目」,而不是「正文文本」。
最终得到的 DOCX 文件。上图为正文的截图,样式为「正文文本」,其中的蓝色字体可点击跳转至文末相应的文献;下图为参考文献表的截图,Pandoc 完美地将其转换为 Word 中的样式「书目」,而不是「正文文本」。
Markdown 转换为 PDF
Pandoc 默认可以直接调用 LaTeX 来生成 PDF:
|
|
与前面生成 main.docx 不同,这条命令中,Pandoc 通过调用 xelatex 引擎(中文用户一般选择 xelatex)生成 PDF。如果一切正常没有报错,打开得到的 output.pdf,你会发现参考文献和前面的 main.docx 是一样的:et al. 和 等 的问题依然存在,中文参考文献表排序不正确,这是因为 Pandoc 使用 citeproc 处理参考文献,基于 Citation Style Language 这个 🥦🐔。
既然使用 LaTeX 生成 PDF,怎么能不用 BibTeX/BibLaTeX 来处理参考文献呢?足够方便的是,已有非常完善的 LaTeX 宏包 13 来实现 GB/T-7714-2015 的排版需求:
- 由 Zeping Lee 基于 BibTeX 开发的 gbt7714
- 由 胡振震 基于 BibLaTeX 开发的 biblatex-gb7714-2015
这两个宏包不需要单独安装,都已包含在 TeX 发行版 中。
伟大的 Pandoc 提供了两个选项 --natbib 和 --biblatex,分别转换为 BibTeX 和 BiLabTeX 引用格式的 LaTeX 文件。下面以 灵活性更高的 BiLabTeX 为例进行说明。
Markdown 转换为 LaTeX
使用命令:
|
|
将 Markdown 文件 input.md 转换为使用 BibLaTeX 引用格式的 LaTeX 文件 input.tex,其中 --wrap=none 表示不折行。值得一题的是,Pandoc 有一个选项 -s 可以转换为完全可编译的 LaTeX 文件,但它基于 Pandoc 的默认 LaTeX 模板,个人认为灵活性不是很高。因此,通过上面这行命令得到的 input.tex 是一个没有导言区(preamble)的 LaTeX 文件,直接编译会报错。那么应该如何使用 input.tex 呢?
在 main.tex 中载入 input.tex
为了使用 input.tex,我采取的方式是写一个自定义的 LaTeX 模板 main.tex,用 \input 或 \include 命令载入 input.tex,通过编译 main.tex 得到 PDF。main.tex 的最小示例如下:
|
|
main.tex 控制格式,input.tex 中是内容,通过在 main.tex 中载入 input.tex,顺便实现了「内容与格式分离」🤣️。
调整引号
LaTeX 中引号的书写方式非常特别:
- 双引号为
``text'',输出结果为“text” - 单引号为
`text',输出结果为‘text’
但这是针对西文的写法,而对于中文,直接书写 “双引号”、‘单引号’ 就可以了。
Pandoc 默认开启 smart 扩展,可以将所有引号转换为 LaTeX 的格式,包括包裹中文的引号,这显然不是我们想要的结果。另一方面,ref.bib 中的引号也需要调整,以符合 LaTeX 的规范 14。那么应该如何调整呢?
俗话说:
没有什么文本处理是查找替换不能解决的,如果有,那就需要用到正则表达式。
好吧,这是我编的俗话 🤣️,直接上查找替换的代码:
|
|
上面这几行代码,将 input.tex 中包裹中文的双引号 ``'' 和单引号 `' 分别替换为 “” 和 ‘’;ref.bib 中包裹西文的双引号 “"” 替换为 ``'',单引号 ‘'’ 替换为 `'。
编译 LaTeX
做好了以上准备工作,接下来就可以使用 latexmk 编译 LaTeX,得到最终的 main.pdf,代码如下:
|
|
集中到一起
将前述一系列命令写在一个 Shell 脚本中,命名为 pdf.sh:
|
|
然后在终端执行:
|
|
稍等片刻就会编译完成,得到 main.pdf。
One More Thing
通过以上步骤,我们得到了 main.docx 和 main.pdf。一般情况下,如果对方没有明确指定文件格式,我会给他/她发送 PDF,但又担心可能需要 DOCX(比如有查看字数的需求),怎么办呢?我的解决方法是将 DOCX 作为附件嵌入 PDF 中。
Adobe Acrobat 可以为 PDF 添加附件,但是毕竟要付费,不是人人都能用它。免费的方式是使用 LaTeX 宏包 Navigator 15,以下是一个最小示例:
|
|
使用 PDF Expert 打开编译后得到的 PDF,如下图所示,鼠标点击蓝色字体「Microsoft Word 文档」,wordcount.docx 就会在系统默认的应用程序中打开,除此之外,也可以在左侧「附件」栏看见 wordcount,双击即可打开。
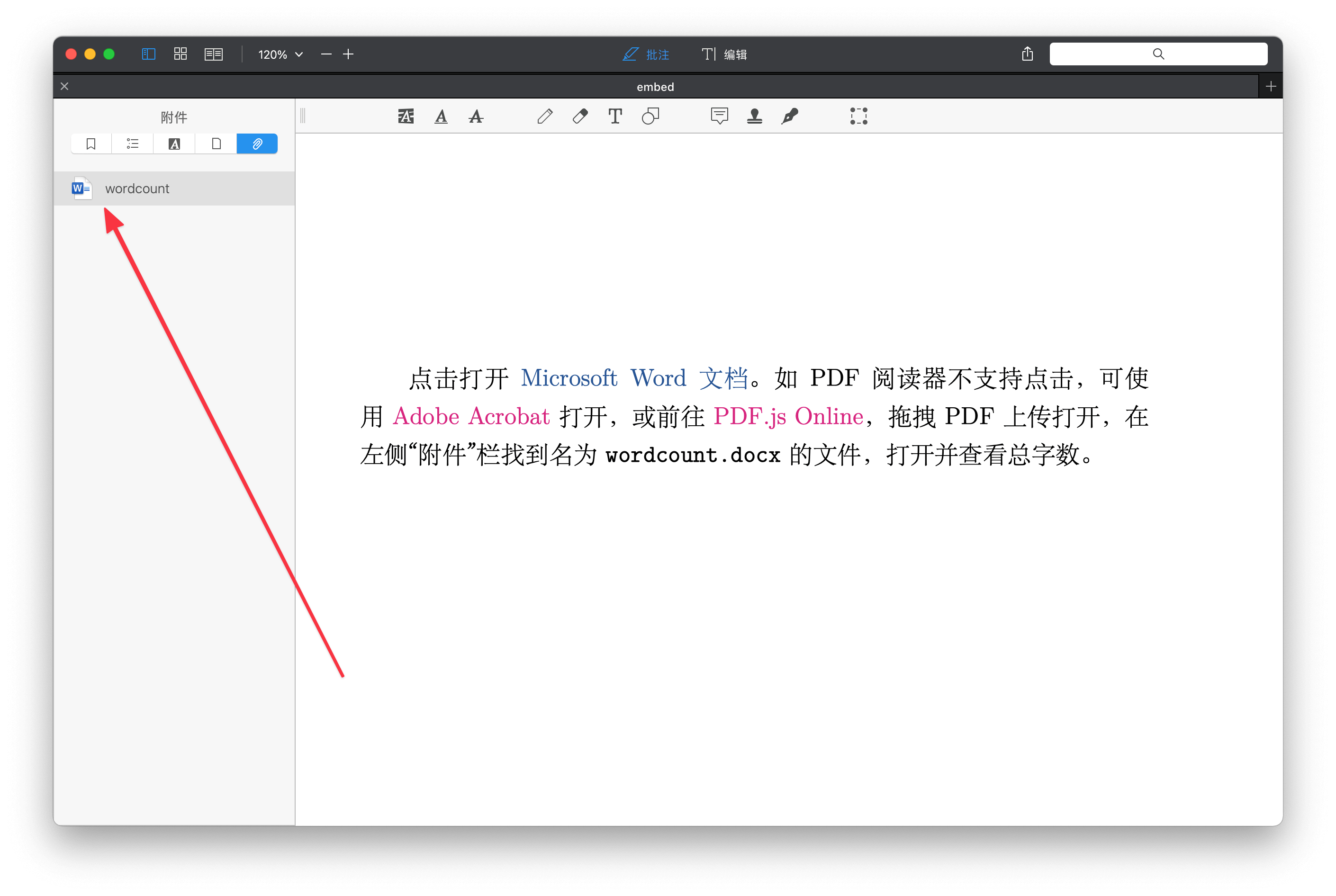 使用 PDF Expert 打开嵌入 DOCX 附件的 PDF
使用 PDF Expert 打开嵌入 DOCX 附件的 PDF
需要注意的是,Navigator 与 BibLaTeX 会产生冲突,如果你需要同时使用这两个宏包,可参考这个 回答 打个补丁,就不会报错了。通过将 DOCX 文件作为附件嵌入 PDF 中,在很多场景下,你只需要给对方发送一份 PDF,他/她就会同时拥有 PDF 与 DOCX 了。
结语
以上提到的所有例子都可以在我的 GitHub 仓库 找到,你可以自由下载并修改,其中的 make.sh 可以一把梭,直接生成 HTML、DOCX 和 PDF,如果你只需要单独得到某一种文件格式,可以进行修改,或者使用 Makefile。需要注意的是,make.sh 在 macOS 测试通过,Linux 应该也能直接用,至于 Windows,应该需要折腾 WSL 或 PowerShell 吧(咱也不懂,逃 🌚)。
在简洁的 Markdown 中写作,通过强大的 Pandoc 将论文转换为 DOCX 和 PDF,结合本文提供的 Shell 脚本进行查找替换,调整一些细节,一把梭得到排版完美的 DOCX 和 PDF,我对目前这套流程还算比较满意,已在几次课程论文与课题撰写中得到了实践与应用,相信对你的学术写作会有所帮助。
在此之前,我也折腾过其他的工具,比如 LaTeX 宏包 Markdown,可以实现 以 Markdown 撰写文稿,以 LaTeX 排版,但由于它目前还有一些局限 16,暂时没有使用了,不过作者提到,在今年有可能实现直接通过该宏包 调用 Pandoc,非常值得期待。除此之外,如果你的文章中有数据处理的需求,能跑代码 的 R Markdown 也是非常值得一试的,甚至还能实现 愉快地写作 🤣️。不论是 Pandoc、Markdown package 还是 R Markdown,都为我们在 Microsoft Word 之外提供了更多的选择,对其在文字处理领域的 统治地位 发起了挑战!
-
这一方式被 Kieran Healy 教授称为「办公室模式」(The Office Model) ↩︎
-
从 Word 中调出 Zotero 的引用面板,总感觉卡卡的 😔️ ↩︎
-
幸运的是,我的本科学校并没有强制要求提交 DOCX 格式的毕业论文,尽管后来要求提交一个缩写版的 DOCX 文件。 ↩︎
-
归根结底就是一句话:来用 Markdown 吧,准没错!😎️ ↩︎
-
BibTeX 和 BibLaTeX 的文件后缀名都为
.bib,文件内容上的差别在于著录项目的名称和种类不同,二者的详细比较可以阅读这个 回答。 ↩︎ -
如果不指定引文样式,Pandoc 默认使用 chicago-author-date。 ↩︎
-
事实上,Zotero、Mendeley 等基于 Citation Style Language 的工具都无法实现多语言混排参考文献的需求。 ↩︎
-
能用纯文本解决的事坚决不在 Microsoft Word 中去点点点 🤪️ ↩︎
-
2023 年 2 月 6 日更新,Pandoc 3.0 更新后,中文标点符号后无需手动追加一个空格也可转换 citekey。因此,一般情况下,这一步已不再需要了。 ↩︎
-
个人认为句中引用左侧没有标点符号的话,空格可以保留,即
@li2018, @feng2019前的空格可以不用移除。 ↩︎ -
参见 Quotation mark - Wikipedia。如果简体中文可以像 中文文案排版指北 建议的那样,使用直角引号「」和『』的话,那就省事多了。 ↩︎
-
比菜鸡的 Citation Style Language 强大多了 🤣️,生成的参考文献完全符合 GB/T-7714-2015 的要求,不需要额外调整。 ↩︎
-
Better BibTeX for Zotero 有一个选项可以 将 Unicode 字符导出为 LaTeX 的纯文本命令,但除了引号以为,它也会将其他一些字符如
——导出为\textemdash\textemdash,在转换为 DOCX 时无法被正确识别,因此我没有开启这一选项。 ↩︎ -
比如对图片、表格的交叉引用支持很弱,无法使用删除线语法(strikethrough syntax)等。 ↩︎